OASIS — Social Media Simulation at One Million Agents
A scalable LLM-agent simulator for X and Reddit that pushes agent counts to one million, replicates real-world information spreading, and reveals that herd effects require more than 100 agents to emerge.
Background
LLM-based social simulation has followed two tracks since Park et al.’s Smallville (2023). One track — including CAMEL, Generative Agents, and AgentSociety — emphasizes environmental fidelity and psychological grounding, running dozens to a few thousand agents through richly modeled worlds. The other track, typified by classical agent-based models (ABMs) in computational social science, reaches millions of agents by stripping the agent model down to a few rules.
The gap matters because the phenomena social scientists most want to study — cascade formation, polarization bifurcation, viral misinformation — are statistical properties of large populations. You cannot reliably observe a cascade with 100 agents any more than you can observe Brownian motion with 10 particles. OASIS asks what it takes to run LLM agents — with genuine natural language comprehension, context-sensitive action selection, and the ability to generate original posts — at the scale where these phenomena actually occur.
The work comes from the same CAMEL-AI group (KAUST, Shanghai AI Lab, Oxford) that built the CAMEL role-playing protocol. Where CAMEL studied two-agent task completion, OASIS studies million-agent social dynamics.
Core Idea
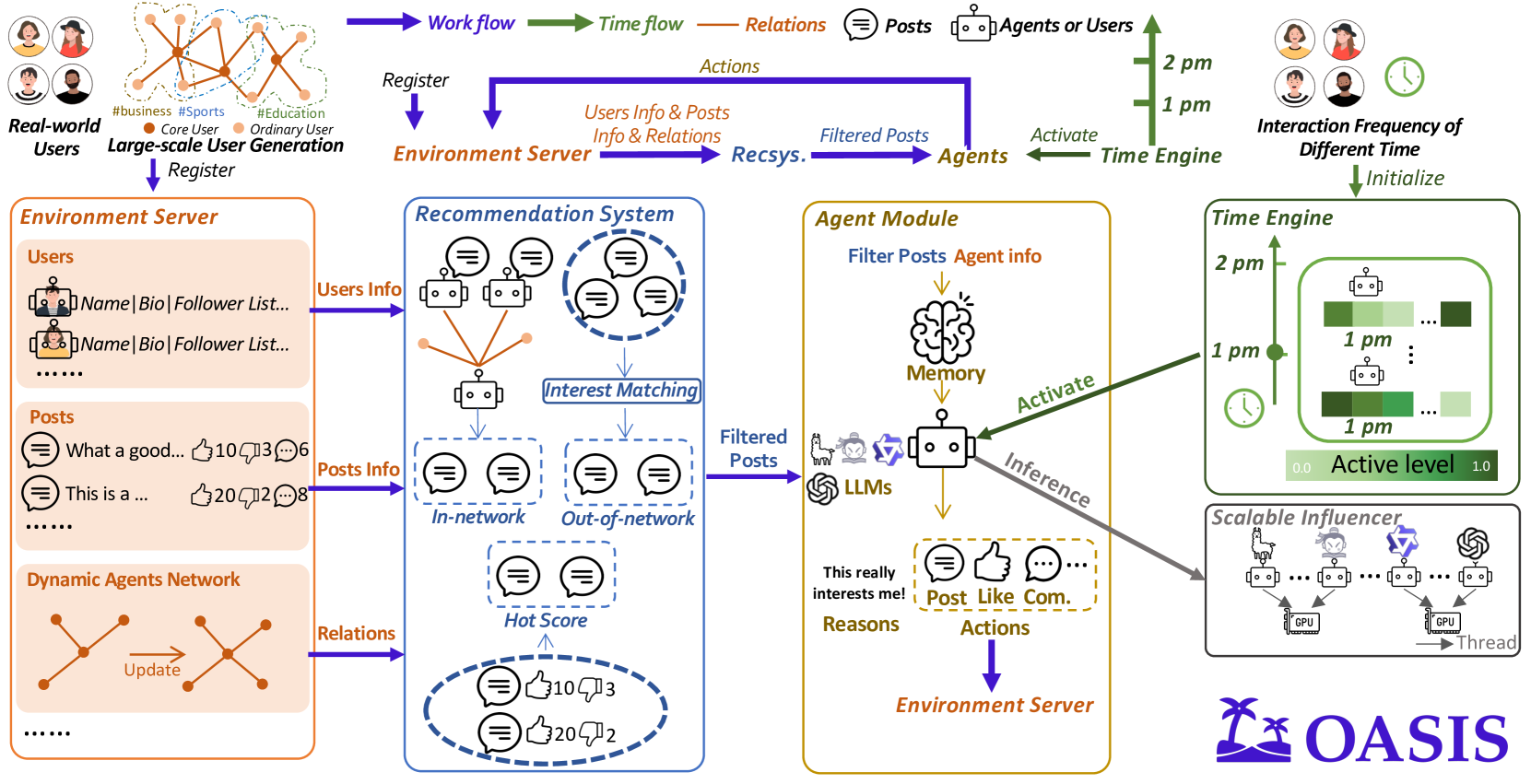
The platform is modeled explicitly rather than abstracted. Agents operate against an environment server that persists real platform state: user accounts, posts, comments, relationships, trace logs, and recommendation queues. Each agent’s action changes this shared state, which in turn updates the next agent’s observation — the feedback loop that produces emergent social dynamics.
Crucially, the recommendation system is not uniform. OASIS implements two platform-specific algorithms that approximate the actual feed-curation mechanics:
X (Twitter): In-network posts are ranked by engagement (likes, reposts). Out-of-network posts are matched by semantic similarity using TwHIN-BERT embeddings against the user’s historical interaction profile. This is the mechanism through which ideological bubbles can form without any explicit “show only agreeable content” rule.
Reddit: Posts are ranked by the hot-score formula disclosed in Reddit’s own documentation:
where is upvotes, is downvotes, and is seconds since the epoch. Recency and net votes both matter; the logarithm compresses vote margins.
Method
Agent design and action space
Each agent is initialized with a synthetic profile (demographics, interests, posting history) and receives a timeline assembled by the recommendation engine at each timestep. The agent selects one action from 21 options: sign_up, create_post, repost, follow, unfollow, like, unlike, dislike, create_comment, like_comment, unlike_comment, dislike_comment, mute, unmute, search, refresh, trend_discovery, do_nothing, and several others. The subset of available actions varies by experiment to match the scenario.
The LLM is queried once per agent per timestep with a prompt containing the agent’s profile, the current timeline, and a structured action schema. The output is parsed into a structured action that is applied to the environment server.
Scalable inference
The inference bottleneck at large agent counts is not the environment server but the LLM throughput. OASIS addresses this through:
- Asynchronous batching: agents whose LLM calls are in-flight do not block others. The GPU manager routes requests across available hardware and returns results as they complete.
- vLLM: continuous batching maximizes GPU utilization across concurrent agent requests.
- Decoupled environment processing: deterministic operations (database updates, recommendation score computation) run in parallel with LLM calls.
At 100K agents over 10 timesteps, the simulation runs for approximately 2 days on 5 A100 GPUs. The 1M-agent ceiling is a reported capacity bound, not the scale of the reported experiments.
Experimental setup
Three core phenomena are studied: information spreading, group polarization, and herd effects. Each uses a subset of the 21 actions appropriate to the phenomenon. Agent counts range from 196 to 10,196 for polarization and herd experiments, and scale to much larger counts for the information-spreading comparison against real X data.
Experiments
Information spreading. Simulated X propagation is compared against real-world cascade data on several trending topics. OASIS achieves approximately 30% normalized RMSE on scale (total reach) and maximum breadth (peak hourly spread). Depth — the longest repost chain — is underestimated, which the authors attribute to the synthetic network being denser and more symmetrically connected than the real sparse-core/dense-periphery Twitter graph.
Group polarization. Agents debate a contested topic over multiple rounds. Opinion distributions widen with interaction — a standard polarization finding. The more striking result is that larger agent groups (10,000+) produce more diverse final opinion distributions than smaller ones (196 agents), where opinions tend to collapse toward a single attractor. Scale increases both the magnitude of extremism and the diversity of the surviving positions, consistent with the intuition that small groups are more susceptible to cascade-to-consensus.
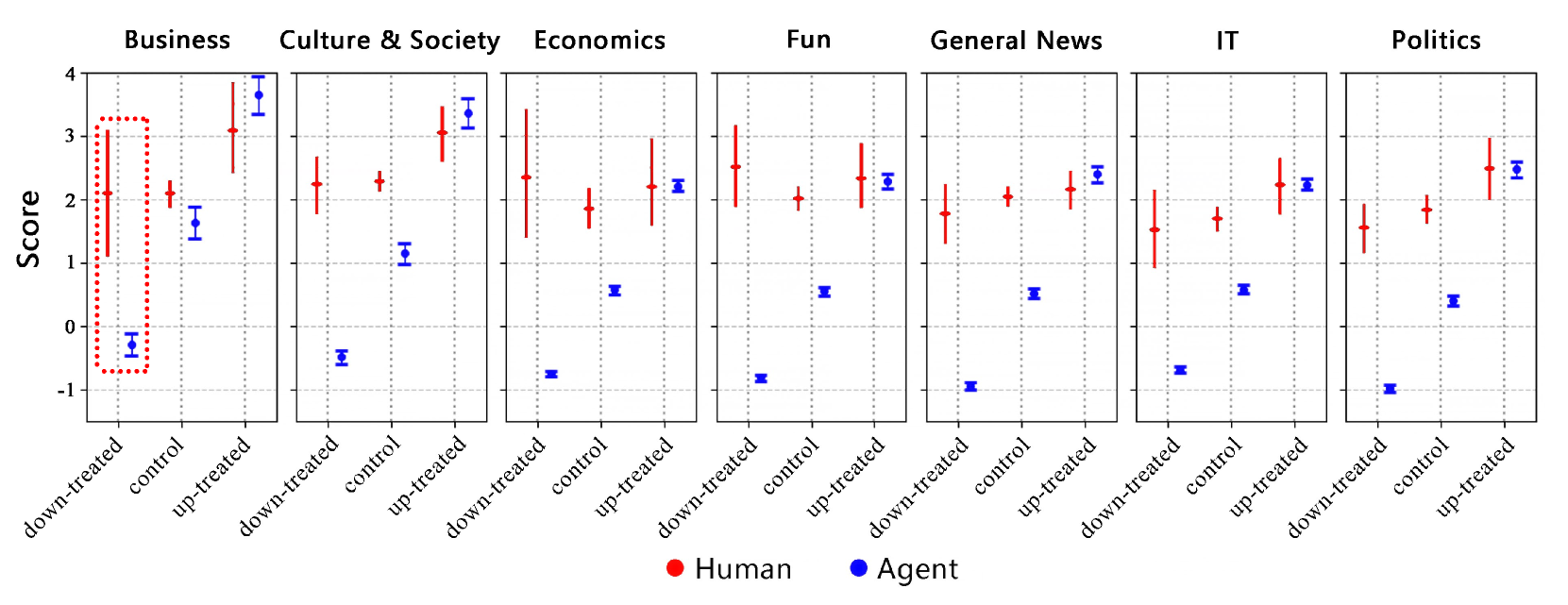
Herd effects. The herd effect experiment presents agents with posts that have been artificially up- or down-voted, then observes whether subsequent agents follow the crowd. Two findings are notable. First, LLM agents exhibit stronger herding behavior than human participants across all seven Reddit topic categories tested. Second, and more practically useful, herd effects do not emerge reliably below 100 agents — the statistical signal is too noisy. Above 10,000 agents, the effect is pronounced and reproducible.
| Phenomenon | Agent scale for reliable detection | Notes |
|---|---|---|
| Information spreading | 1,000+ | Cascade shape requires sufficient path diversity |
| Group polarization | 500+ | Smaller groups collapse to consensus |
| Herd effects | 100+ | Effect absent at 196, pronounced at 10,196 |
Compute cost. 100,000 agents, 10 timesteps: ~2 days, 5 A100 GPUs. This is the practical ceiling for routine experiments.
Limitations
Three limits the authors acknowledge directly. First, synthetic user profiles: agent personas are generated rather than sampled from real platform demographics, which means ideological, linguistic, and behavioral distributions may not match real platform populations. Downstream social phenomena are sensitive to these distributions. Second, simplified recommendation models: the TwHIN-BERT-based recommendation approximates semantic matching but does not capture the full engagement-optimization objective of real platform algorithms, which incorporate dwell time, creator-follower relationships, and user-level A/B variants. Third, the compute ceiling is real: the 1M-agent claim is an infrastructure capacity figure, not the scale of the reported experiments. Running a controlled 1M-agent experiment long enough to observe emergent phenomena remains outside current practical reach.
A fourth interpretive caution: LLM agents showing stronger herding than humans may reflect fine-tuning toward agreeableness rather than genuine social dynamics. Separating intrinsic herding from RLHF-induced agreeableness is not addressed in the paper.
References
- Original paper: OASIS: Open Agent Social Interaction Simulations with One Million Agents
- Code: camel-ai/oasis
- CAMEL (predecessor, same group): Li et al. (2023), arXiv:2303.17760
- AgentSociety (complementary approach): Piao et al. (2025), arXiv:2502.08691
- Generative Agents (small-scale predecessor): Park et al. (2023)
- TwHIN-BERT: El-Kishky et al. (2022), arXiv:2209.07562
- Reddit hot-score algorithm: disclosed by Reddit, reproduced in OASIS Appendix