MemPalace — Verbatim Memory for LLM Agents, Benchmarked Honestly
An open-source local-first memory system that stores conversation history verbatim, organizes it into a hierarchical palace structure, and achieves 96.6% R@5 on LongMemEval without any LLM or API key.
Background
LLM memory research has converged on two paradigms. Extraction-based memory (Mem0, Zep, OpenAI’s memory feature) runs an LLM at write time to identify “important” information and discard the rest. Summarization-based memory collapses sessions into progressively shorter abstractions. Both paradigms make an irreversible decision at write time: what gets dropped stays dropped.
The failure mode is predictable. A user mentions their daughter’s allergy in turn 7 of session 3. An extraction pipeline might not flag this as “important”. A summarization pipeline compresses it into “user has a child”. When the user returns four sessions later and asks for a dinner recommendation, the specific allergy is gone from the retrievable store.
LongMemEval (2024) was designed to stress-test exactly this scenario: 500 questions spanning knowledge updates, multi-session reasoning, temporal queries, and single-session facts, evaluated against conversation histories of 100–500 turns. A system that extracts selectively will fail on questions whose answers depend on details the extractor deemed unimportant.
MemPalace’s premise is that the extraction decision belongs at query time, not write time. Store everything verbatim; decide relevance only when you know the question.
Core Idea
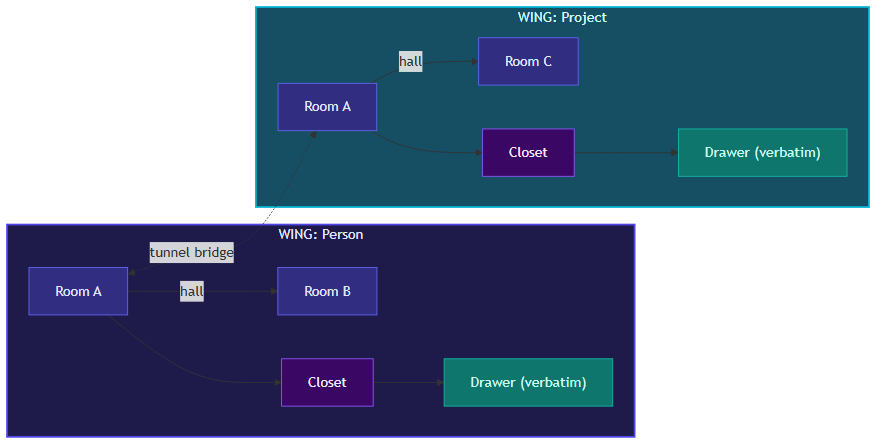
The “palace” metaphor is structural, not cosmetic. The hierarchy maps to real retrieval constraints:
- Wings are top-level partitions, typically one per project or long-running context. Scoping search to a wing eliminates cross-context noise without requiring the LLM to reason about it.
- Rooms are topic-level partitions within a wing. The current default splits content into five conceptual halls (travel, work, health, relationships, general).
- Drawers are the atomic storage unit — one per conversation session by default, or one per user/assistant message turn in fine-grained mode (
mempalace sweep).
Content is stored as verbatim text. The only transformation at write time is chunking and embedding (sentence transformers, ~300 MB model, runs locally). No LLM is invoked, no API key is needed, nothing is discarded.
Method
Raw retrieval
The base retrieval layer is straightforward: embed the query, compute cosine similarity against all stored drawer embeddings, return the top-K results. No heuristics, no reranking. This “raw mode” achieves 96.6% R@5 on LongMemEval — meaning the correct session appears in the top-5 results 96.6% of the time across 500 diverse questions.
The strength of this baseline is itself informative. Most retrieval-augmented memory literature implicitly assumed that raw vector search would underperform, motivating elaborate extraction pipelines. MemPalace’s raw result suggests the assumption was wrong, or at least that the failure case (what does raw search miss?) is smaller than the field assumed.
Hybrid pipeline (v4)
The hybrid pipeline layers five additional signals on top of the raw embedding similarity:
- Keyword overlap boost: exact terminology match between query and drawer receives a mild score increase.
- Temporal proximity boost: drawers close in time to the query’s implied date receive up to 40% distance reduction.
- Quoted phrase extraction: exact phrases in quotes receive 60% distance reduction.
- Person name boosting: capitalized proper nouns receive 40% distance reduction.
- Preference pattern extraction: 16 regex patterns detect implicit preferences (“I usually prefer X”, “I don’t like Y”) and boost matching drawers.
Trained on a 50-question dev set, the hybrid pipeline achieves 98.4% R@5 on the held-out 450 questions — the honest generalisable figure. The 50-question tuning set is explicitly flagged in the benchmark documentation to prevent confusion with generalization performance.
Knowledge graph
Alongside the vector store, MemPalace maintains a temporal entity-relationship graph backed by SQLite. Entities (people, projects, places) carry validity windows: relationships can be added, queried, invalidated, and displayed as timelines. This layer is for structured facts that need point-in-time retrieval rather than semantic similarity search.
MCP server and agent integration
Twenty-nine MCP tools cover palace reads and writes, knowledge-graph operations, cross-wing navigation, drawer management, and agent diaries. Each specialist agent gets its own wing and diary, discoverable at runtime via mempalace_list_agents without requiring a bloated system prompt. For Claude Code specifically, two hooks handle auto-save: one periodic hook and one pre-compression hook that fires before context compaction.
Benchmarks
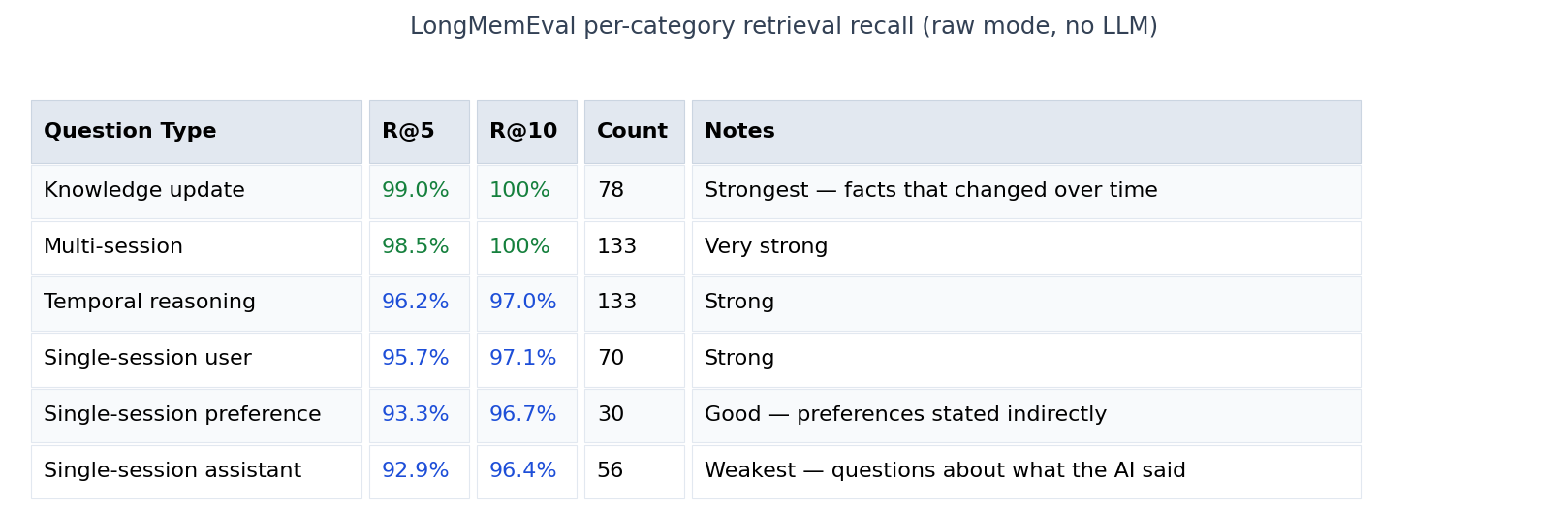
All benchmark numbers are reproducible from the public repository; full per-question result files are committed under benchmarks/results_*.jsonl. The benchmark methodology explicitly separates retrieval recall (R@K: does the correct session appear in top-K?) from end-to-end QA accuracy (does the system produce the correct answer?) — these are different metrics that prior comparison tables had conflated.
LongMemEval (500 questions):
| Mode | R@5 | LLM required |
|---|---|---|
| Raw (verbatim + embedding, no heuristics) | 96.6% | None |
| Hybrid v4, held-out 450q | 98.4% | None |
| Hybrid v4 + LLM rerank (full 500) | ≥99% | Any capable model |
The rerank pipeline promotes the best candidate out of the top-20 retrieved sessions using an LLM reader. The gap between raw and reranked is model-agnostic — reproduced with Claude Haiku, Claude Sonnet, and minimax-m2.7 via Ollama. The 99%+ number is not headlined because the last 0.4% was reached by inspecting specific wrong answers (benchmarks/BENCHMARKS.md flags this as “teaching to the test”).
LoCoMo (1,986 multi-hop questions):
| Mode | R@10 |
|---|---|
| Hybrid v5 (no rerank) | 88.9% |
| Palace v2 (3 rooms, routing at index) | 84.8% |
ConvoMem (250 items, 5 categories): 92.9% average recall. Strongest on user facts (98.0%) and assistant facts (100%); weakest on preferences (86.0%).
MemBench — ACL 2025 (8,500 items): 80.3% R@5. Near-perfect on aggregative (99.3%) and comparative (98.4%) categories; weakest on noisy (43.4%) and conditional-reasoning (57.3%) categories, where distractors are deliberately introduced.
The MemBench weakness is the honest limit of verbatim storage: when irrelevant content is deliberately mixed in, higher recall of the full session also recalls the distractors. Filtering distractors requires reasoning, which raw embedding cannot do.
Limitations
Four limits worth flagging. First, verbatim storage plus noisy queries: the 43.4% R@5 on the MemBench “noisy” category reflects what happens when irrelevant content is interspersed with relevant content in the same session — embedding similarity retrieves the whole session, distractors included. Post-retrieval LLM reading can mitigate this but reintroduces API dependency. Second, AAAK compression mode trades fidelity for token density (84.2% vs 96.6% R@5 on LongMemEval — a 12.4pp regression) and should not be treated as equivalent to raw mode for retrieval-sensitive applications. Third, temporal persona management is unresolved: the framework handles fixed time windows independently, but incrementally updating an existing persona bank as the user’s behavior evolves over months requires a merge strategy that is not yet implemented. Fourth, the benchmark corrections documented in docs/HISTORY.md are notable: a community audit (April 2026) identified metric-comparison errors and overstated claims in the initial release that required table rewrites across multiple surfaces.
References
- Repository: MemPalace/mempalace — v3.3.4 at time of writing
- Documentation: mempalaceofficial.com
- Benchmark corrections and history: docs/HISTORY.md
- Benchmark methodology: benchmarks/BENCHMARKS.md
- LongMemEval: Wu et al. (2024), arXiv:2407.01437
- LoCoMo: Maharana et al. (2024), ACL 2024
- MemBench: arXiv:2506.21605 (ACL 2025)
- Mem0 (extraction-based alternative): mem0.ai
- ChromaDB (default vector backend): trychroma.com