Simulating 1,000 People — Generative Agents From a Single Interview
A Stanford team injects two-hour qualitative interviews of 1,052 real individuals into an LLM and predicts their attitudes and behaviors at the individual level.
Background
Prior work using LLMs as “proxy humans” took two routes. One prompts on demographic attributes (age, gender, race, ideology) and asks “how would such a person answer”; the other attaches a short persona paragraph. Both are convenient, but a growing literature finds that they tend to flatten minority groups toward stereotypes and to match only average treatment effects. The agent-based-modeling tradition, in contrast, hand-specifies behaviors to preserve interpretability, at the cost of generality outside narrow domains.
This paper closes a specific gap. Social scientists have long used in-depth interviews to capture idiosyncrasies that closed-form surveys miss. The authors feed those transcripts verbatim to an LLM to target individual-level prediction. Evaluation also shifts: not “did we recover a population-average effect” but “did we predict this specific person’s response as well as they predict themselves two weeks later.”
Core Idea
The architecture has three pieces. First, an AI interviewer runs a semi-structured protocol from the American Voices Project, collecting on average 6,491 words of transcript per participant (roughly two hours of voice). Second, that transcript becomes the agent’s memory stream. Third, at query time, the entire transcript plus relevant “expert reflections” is injected into the LLM prompt.
Expert reflection is the architecturally distinctive move. Per participant, GPT-4o is prompted four times, each time adopting a different domain-expert persona (psychologist, behavioral economist, political scientist, demographer), producing 5-20 observations or inferences per expert. At query time the model first classifies which expert is most relevant to the question, then appends that expert’s reflections to the transcript before generating the final prediction. It is a scaffold for latent traits a single chain-of-thought pass would skip.
Method
3.1 Interview protocol
The sample is 1,052 US residents recruited by Bovitz, stratified on nine axes: age, census division, education, ethnicity, gender, income, neighborhood, political ideology, and sexual orientation. Interviews are voice-to-voice in English, conducted by an AI interviewer pipelining Whisper, GPT-4, and TTS. The protocol ranges from “tell me the story of your life” to views on race relations and policing. A deliberate design choice: the interview topics do not overlap with the evaluation instruments — the specific items of the GSS, BFI-44, and economic games are never asked. High downstream accuracy therefore reflects generalization rather than prompt leakage.
3.2 Agent architecture
At query time the flow is: (1) load the transcript into memory; (2) retrieve pre-generated expert reflections (cached offline, four personas); (3) have the LLM pick the most relevant expert for the question and append those reflections after the transcript; (4) prompt GPT-4o with chain-of-thought to produce the prediction. Multi-step decision tasks add short textual summaries of prior stimuli and responses to preserve continuity. Two baselines anchor the comparison: a demographic-based agent seeded with age, gender, race, and ideology extracted from the participant’s GSS answers, and a persona-based agent using a self-written paragraph by the participant.
3.3 Evaluation battery
Four instruments. (i) GSS core module, 177 items (mean 3.70 options per question, chance accuracy 27.03%). (ii) Big Five, the 44-item BFI. (iii) Five economic games — dictator, trust (both roles), public goods, prisoner’s dilemma — played for real monetary incentives. (iv) Five experimental replications drawn from a recent large-scale replication effort (Ames & Fiske 2015; Cooney et al. 2016; Halevy & Halali 2015; Rai et al. 2017; Schilke et al. 2015). Participants complete the battery twice, two weeks apart. The main dependent variable is normalized accuracy: the agent’s prediction accuracy divided by the participant’s own two-week self-replication rate. A value of 1.0 means the agent predicts the participant as well as the participant predicts themselves.
Experiments
| Configuration | GSS normalized accuracy | Big Five normalized correlation | Economic-games normalized correlation |
|---|---|---|---|
| Interview-based | 0.85 | 0.80 | 0.66 |
| Persona-based | 0.70 | 0.75 | — |
| Demographic-based | 0.71 | 0.55 | — |
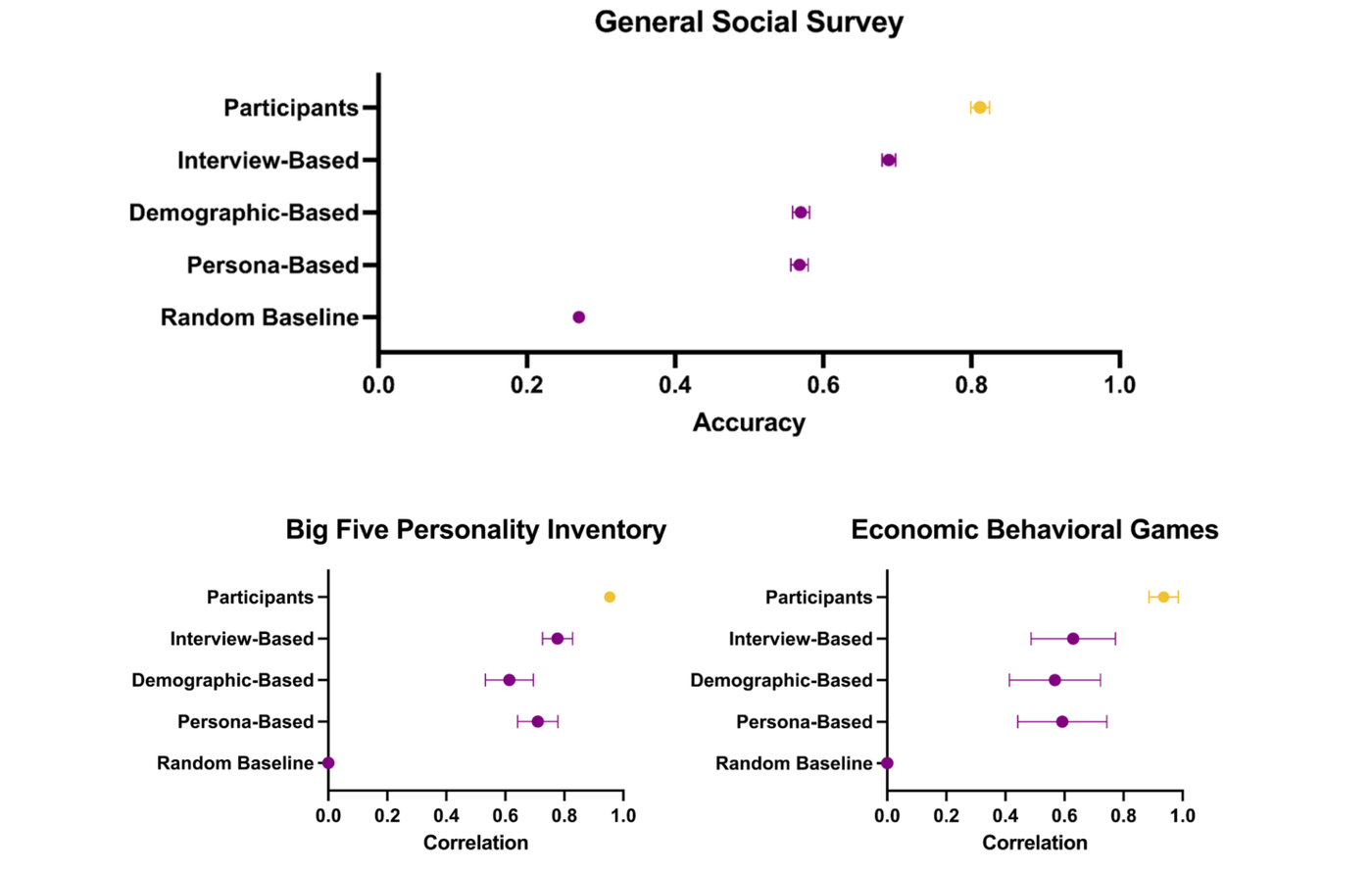
Raw GSS accuracy is 68.85%; participants’ own two-week self-replication is 81.25%. Interview-based agents lead both baselines by 14-15 normalized points, confirmed by ANOVA and Tukey post-hoc tests. Big Five shows the same ordering. Economic games show no significant MAE difference across the three conditions. On the replication studies, human participants replicate four of five; interview-based agents replicate the same four. Effect-size correlation between agents and humans is r = 0.98, essentially indistinguishable from participants’ own internal consistency (0.99).
The bias analysis is where the architecture’s second claim lands. Demographic Parity Difference (DPD) — the gap between the best and worst performing subgroup — falls on the ideology axis from 12.35% (demographic agent) to 7.85% (interview agent) on GSS, from 0.165 to 0.063 on Big Five, and from 0.50 to 0.19 on economic games. Racial subgroups shrink somewhat as well. Richer individual context reduces between-group accuracy gaps. Ablations reinforce the story. Randomly dropping 80% of the transcript (96 of 120 minutes) still yields 0.79 on GSS, and replacing the transcript with a bullet-point summary keeps GSS at 0.83. The driver appears to be information richness rather than linguistic signal.
Limitations
The main constraints are access policy and domain scope. Citing participant privacy, the authors withhold raw interviews and gate the agent bank behind a two-pronged system: open access to aggregated responses on fixed tasks, restricted API access to individualized responses on open tasks for approved researchers. That slows external replication. The sample is US adults only, and the economic-games result is not significantly better than the baselines — the architecture’s lift is task-dependent.
The authors also flag structural limits. Prompt-loading the full transcript is expensive and susceptible to long-context degradation (lost-in-the-middle). Results are tied to a single backbone (GPT-4o at the time of evaluation) and only five experimental replications, constraining external validity. Extrapolation to stakeful decisions — markets, strategic negotiation, incentive-compatible reporting — is not guaranteed by these measurements.
References
- Original paper: Generative Agent Simulations of 1,000 People
- Code: joonspk-research/generative_agent
- Prior architecture: Park et al. (2023) Generative Agents: Interactive Simulacra of Human Behavior; Argyle et al. (2023) Out of One, Many
- Interview protocol: American Voices Project, Stanford Center on Poverty and Inequality