AgentSociety — City-Scale LLM Social Simulation
A Tsinghua FIB Lab platform that drives 10,000 LLM agents through a real urban, economic, and social environment and reproduces four field social experiments on a single stack.
Background
LLM social simulation has bifurcated in the past two years. On one side sit Smallville-style stacks (Park et al. and descendants) that model rich minds for tens to hundreds of agents. On the other sit systems like OASIS that simplify the environment substantially and push agent counts to hundreds of thousands. Both sides face a similar trade-off. The first does not scale to population-level experiments; the second loses the environmental fidelity that keeps results legible against real-world outcomes.
The authors frame the gap along three axes: (1) whether the agent’s mind is grounded in psychology and behavioral science rather than ad-hoc role-play, (2) whether the environment captures the physical and economic constraints of a real city, and (3) whether the engine can drive 10k+ agents under asynchronous interaction without collapsing. Laying 17 prior simulators on these axes shows no platform clears all three. AgentSociety targets that empty cell.
Core Idea
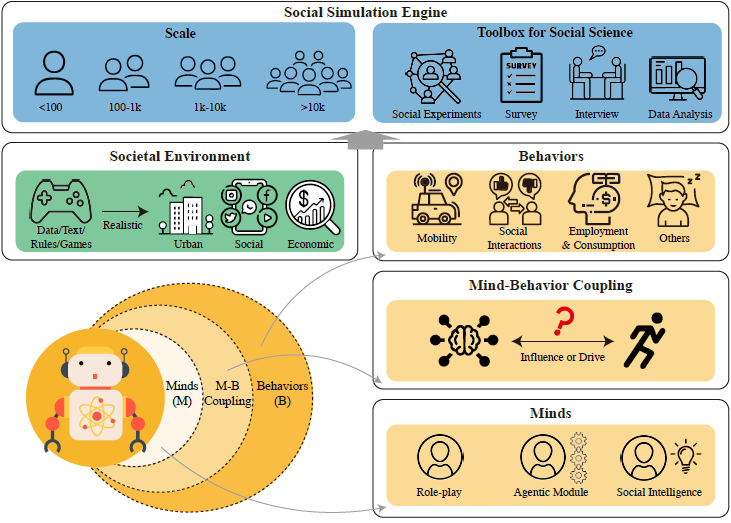
The backbone is a closed mind-to-behavior-to-feedback loop. Each agent carries a static profile (demographics, personality) and a dynamic status (emotion, needs, cognition, economic position, social ties). Emotion — six basic affects at 0-10 intensity — provides the fast response layer. Needs, structured as a Maslow hierarchy, act as the persistent motivational driver. Cognition stores attitudes on topics and produces thoughts that feed back into future prompts. Behaviors are split: mobility, social interaction, and employment/consumption are modeled explicitly, while simpler actions (sleep, leisure choice) are handled by the LLM directly.
The move that separates this work from text-world simulators is that the environment is not text. Urban space is built from OpenStreetMap road networks, SafeGraph POIs, and AOIs, with driving (IDM acceleration, MOBIL lane-change), walking, bus, and taxi dispatch modeled as discrete-time physics. Social space layers a relationship graph with a “supervisor” middleware that can filter messages or ban users. Economic space runs firms, households, banks (Taylor-rule interest), and a government (progressive tax) as an accounting system — a stripped-down DSGE that settles every step.
Method
3.1 Agent cognition
Mind-behavior coupling is done through theory-grounded modules rather than a single monolithic prompt. Emotion follows Shvo et al.’s framework: the LLM selects a keyword, writes a sentence thought, and rates six emotions from 0-10. Needs are a Maslow-structured JSON hierarchy re-ranked each step by active behavior, passive events, and current mental state. When a need rises to the top, the Theory of Planned Behavior produces a Need → Plan → Behavior Sequence chain. Cognition maintains a per-topic 0-10 attitude store that is updated by sentence-level summaries of completed behaviors, so attitudes and emotion move in lockstep.
Memory is three-tier. A static Profile, a dynamic key-value Status, and a time-ordered Stream Memory split into an Event Flow (objective occurrences) and a Perception Flow (the agent’s read of those events). Perception nodes link back to event nodes, giving the agent a coupled objective-subjective history that prompts the next decision.
3.2 Environment and social graph
Mobility is decomposed into four steps: (i) extract intent from active needs, (ii) filter POI types (social need → cafes, parks), (iii) set a radius from internal state (age, stamina) and external state (weather, traffic), (iv) choose the destination with a gravity model . Replacing the final LLM call with a deterministic model is the load-bearing choice; it preserves spatial rationality at scale and cuts token cost.
The social graph carries three relationship types (family, friend, colleague) each with a 0-100 strength. Target selection for a message factors relationship, strength, and topical fit, and tone shifts by relationship type. Online interaction is the primary mode. A supervisor middleware sits before message delivery and can classify content via an LLM, then apply node interventions (suspend accounts) or edge interventions (remove connections). This plumbing is what the inflammatory-messages experiment in 7.3 actually tests.
3.3 Simulation infrastructure
The engine is the quiet contribution. Two concrete bottlenecks shaped the design. First, treating each agent as its own process exhausts the 65,535 TCP ports the MQTT broker, database, and metric server can advertise, well before 10k agents. Second, SOP-driven frameworks like CAMEL and AgentScope impose an execution order on agent turns, which contradicts the independent-decision premise the simulation is supposed to capture.
The fix is three moves. Agents are batched into groups; each group runs as one Ray actor that reuses a single connection to each shared service. LLM calls are I/O-bound, so asyncio coroutines hide request latency while CPU cycles run deterministic work like the gravity model. Inter-agent messaging uses MQTT (emqx v5.8.1) — an IoT protocol tuned for millions of lightweight endpoints.
| System | Best parallel process count | Throughput (msg/s) |
|---|---|---|
| MQTT (emqx v5.8.1) | 32 | 44,702 |
| Redis Pub/Sub (v6.2) | 16 | 81,216 |
| RabbitMQ (v4.0.5) | 16 | 23,667 |
| Kafka | — | fails to initialize in 5 min |
Redis wins raw throughput, but MQTT’s built-in observability tooling and topic-tree semantics decided the default. On the environment side, a 1M-agent load test holds a mean step time of 0.168 s at 10⁵ QPS — a headroom test rather than the experiment setup. Experiments use DeepSeek-V3 on Huawei Cloud c7.16xlarge.4, scheduled during the 05:00-07:00 off-peak window because LLM API throughput is what actually caps scale.
Experiments
The value of the platform is that four distinct experiments run on the same codebase.
Polarization (7.2). A 100-agent panel debates gun control. The control group runs free, a homophilic treatment feeds each agent only persuasive messages aligned with their prior, and a heterogeneous treatment feeds only opposing messages. Control: 39% polarize further, 33% moderate. Homophilic: 52% polarize — the echo-chamber prediction. Heterogeneous: 89% moderate, 11% flip. Directionally aligned with lab results in political science.
Inflammatory messages (7.3). Seeded by a real case (the chained woman in Xuzhou), the simulator compares neutral and inflammatory seeds across a few hundred agents, with node and edge interventions layered on. Inflammatory seeds reach farther and raise emotional intensity; node interventions outperform edge interventions on both reach and affect. Interviews with the agents surface sympathy and perceived social responsibility as the main sharing motives.
Universal Basic Income (7.4). Demographics match Texas. Two runs — with and without a $1,000/month unconditional transfer introduced at step 96 — are compared over the next 24 steps. Consumption rises and CES-D depression scores fall under UBI, directionally matching the Texas field result. Agent interviews mention interest rates, long-term benefit, savings, and necessities — vocabulary that overlaps the real UBI discourse.
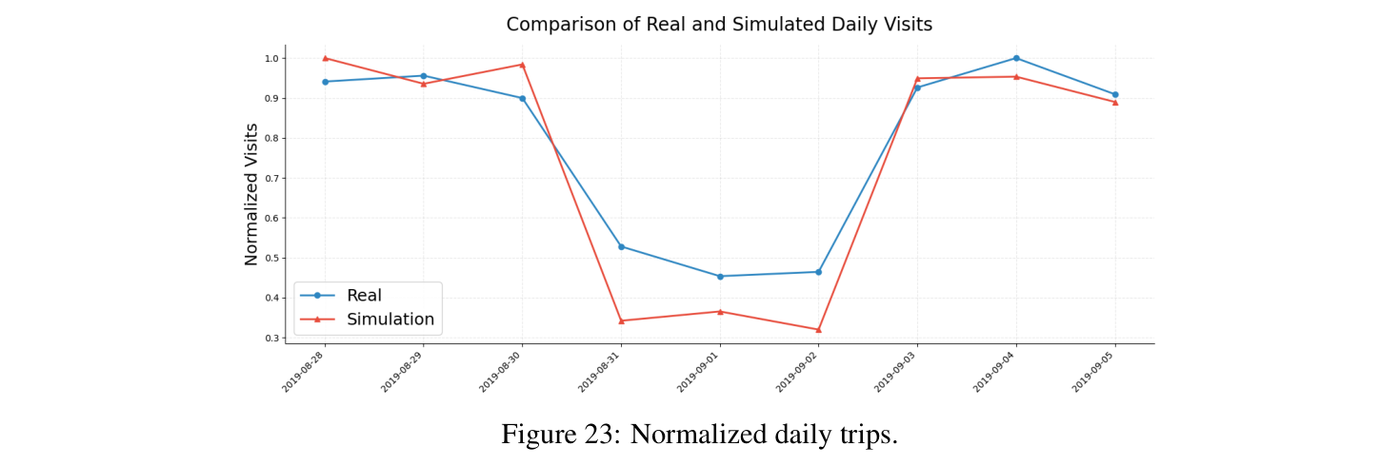
Hurricane Dorian (7.5). Columbia, South Carolina in 2019. Before arrival, Census Block Group activity ratios sit at 70-90%; during the storm they fall to ~30% and recover afterward. Simulated daily visits track SafeGraph ground truth on timing, with some underestimate of peak magnitude. The behavior change is driven by a single external shock message routed through the messaging system — no hand-coded evacuation rule.
Limitations
The authors open with the economic modeling gap. The goods market is a price adjustment on aggregate demand — no explicit supply curve, competition, or market shocks. The labor market pays wages but has no unemployment or negotiation. The UBI result should therefore be read as directional rather than as a magnitude forecast. Offline social interaction is similarly sketched at the level of spatial proximity.
On the engineering side, LLM API throughput dominates wall-clock time as soon as agent counts rise. The environment holds 10⁵ QPS headroom but the DeepSeek endpoint does not, which is why the experiments hug the 05:00-07:00 window. Fixed-size agent groups are also bottlenecked by the slowest group; adaptive load balancing is named as future work. Results are tied to DeepSeek-V3 as the sole backbone — how the reproduced social effects hold across LLMs is an open question. And while infrastructure scales to 10k agents, the polarization and inflammatory-message experiments themselves run at the 100-agent scale; “10k” describes the infrastructure ceiling rather than the experimental grain.
References
- Original paper: AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents
- Code: tsinghua-fib-lab/agentsociety
- Theoretical grounding: Maslow, Hierarchy of Needs; Ajzen, Theory of Planned Behavior; Smith & Taylor on Dynamic Stochastic General Equilibrium
- Comparison platforms: Park et al. (2023) Generative Agents; Yang et al. (2024) OASIS; Li et al. (2024) EconAgent
- Infrastructure references: Ray, MQTT (emqx), PostgreSQL, OpenStreetMap, SafeGraph