Can AI Agents Agree — When Multi-Agent Consensus Breaks
A controlled study of when and why LLM-agent groups fail to reach agreement in a Byzantine consensus game.
Background
LLMs are increasingly deployed as autonomous agents for planning, coding, and reasoning. When a group must produce a single shared decision rather than independent answers — delegation, voting, safety-critical coordination — the group’s ability to agree becomes a design requirement, not a convenience. Classical Byzantine fault-tolerant (BFT) consensus gives strong guarantees for deterministic algorithms (Pease et al., 1980; Lamport et al., 1982): with agents and at most Byzantine nodes, agreement is achievable if and only if .
The FLP impossibility result (Fischer, Lynch, Patterson 1985) further shows that no deterministic consensus algorithm can tolerate even one faulty node in an asynchronous network. The CAMEL paper’s setting — synchronous all-to-all, bounded rounds — is the favorable case for consensus. Classical algorithms designed for this setting succeed reliably. The striking finding is that LLM-based agents fail to agree in more than half of runs even under these favorable conditions, without any Byzantine agents present.
The authors close that gap with a controlled testbed: a no-stake scalar consensus game. Because agents have no preference over the final value, evaluation isolates “did they agree” from “is the value good.” Unlike prior work on LLM numeric negotiation (Chen et al., 2023), this study (1) controls a Byzantine fraction, (2) enforces a validity constraint — the decided value must belong to the initial honest proposals — and (3) reports validity and liveness as separate axes.
Core Idea
agents exchange scalar proposals over rounds on a synchronous all-to-all network. A fraction are Byzantine and may pick arbitrary values each round. Honest initial proposals are sampled i.i.d. uniform on . In each round an agent receives a textual summary, emits a new proposal and free-text justification, and casts a termination vote . The simulator terminates when at least two-thirds of agents vote to stop; otherwise it times out.
Outcomes decompose into three buckets: (i) valid consensus — all honest agents hold an identical value drawn from the initial honest proposals; (ii) invalid consensus — termination without validity; (iii) no consensus — timeout. This decomposition is the analytic spine of the paper.
Method
3.1 The A2A-Sim protocol
A synchronous all-to-all simulator. Per round, agent (1) receives its local history and current proposal , (2) queries an LLM policy to produce a new proposal and justification , (3) if Byzantine, arbitrarily modifies both, (4) broadcasts to all peers and receives their messages, (5) updates state and emits a termination vote. To respect context limits, the prompt injects a compact summary — per-agent proposals and truncated justifications from the previous round — rather than raw history.
3.2 Threat model and agent implementation
The Byzantine model is deliberately restricted: arbitrary values and justifications, adaptation to history allowed, but no equivocation (cannot send different messages to different receivers), no identity forgery, and no message drops. A Byzantine agent must broadcast a single message to all peers in each round. The paper shows that even this mild threat model is enough to disrupt consensus.
Honest and Byzantine agents share a JSON-output template (proposal, justification, termination decision). Inference uses vLLM batched with guided decoding, FP16/BF16, 8,192-token context. Experiments test Qwen3-8B and Qwen3-14B.
3.3 Evaluation
Each configuration is run 25 times. The authors report outcome rates, rounds to termination, and consensus quality with 95% Wilson intervals, at . Two prompt variants gate the system prompt: May Exist explicitly warns that Byzantine peers may be present; None Exist omits any mention of adversaries.
Experiments
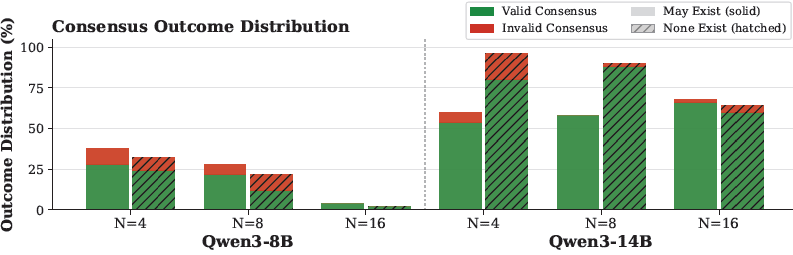
Benign setting (no Byzantine agents). Across 600 simulations the overall valid-consensus rate is 41.6%. Qwen3-14B (67.4%) substantially outperforms Qwen3-8B (15.8%), but both exhibit high timeout rates. Dropping Byzantine mentions from the system prompt moves Qwen3-14B from 59.1% to 75.4% valid consensus and roughly halves convergence time. Group size hurts monotonically: valid consensus falls from 46.6% at to 33.3% at .
| Model | Prompt | Overall | |||
|---|---|---|---|---|---|
| Qwen3-14B | None Exist | ~75% | ~72% | ~54% | 75.4% |
| Qwen3-14B | May Exist | ~65% | ~55% | ~32% | 59.1% |
| Qwen3-8B | None Exist | ~22% | ~16% | ~9% | 15.8% |
(Values read from paper figures; overall column is directly reported.)
With Byzantine agents. With eight honest Qwen3-14B agents and adversaries (fractions from to ), valid consensus collapses. A single Byzantine agent already produces a large drop. Critically, invalid consensus remains rare: Byzantine agents do not steer the group toward corrupted values — they prevent termination. The dominant failure mode is liveness loss, not value corruption.
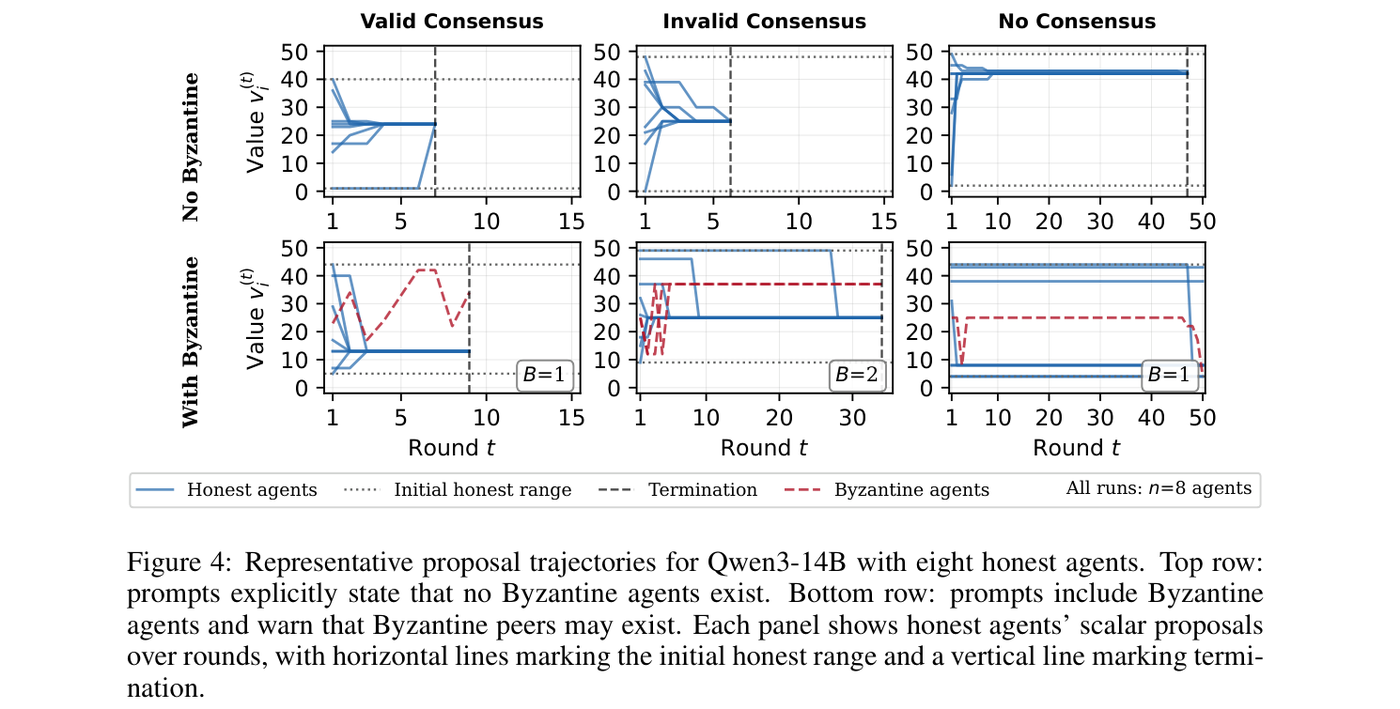
Prompt sensitivity and trajectories. Representative proposal trajectories show that, under threat-free prompts, honest agents contract quickly into the initial honest range; under threat-aware prompts or real Byzantine presence, proposals drift beyond the initial range or stall for many rounds. Even when validity would have held, termination votes fail to cluster and consensus is never declared.
Limitations
Three limits the authors flag directly. First, the Byzantine strategy is a single “arbitrary-with-adaptation” archetype; equivocation (sending different values to different receivers), message drops, and collusion are out of scope. Even mild equivocation would break the synchronous all-to-all assumption and is known to fundamentally change the BFT feasibility threshold. Second, model coverage is two sizes of one family (Qwen3). Third, the network is fixed to synchronous all-to-all — real deployments face partial synchrony, partial connectivity, latency, and loss. Interpretively, the no-stake framing means results do not automatically extrapolate to stakeful consensus where preferences conflict and agents have incentives to deceive.
A fourth limitation implicit in the design: the round limit is generous relative to practical deployment budgets (each round requires LLM calls), and the paper does not report how sensitivity to interacts with the failure-mode distribution. Tight token budgets may push real systems into a qualitatively different liveness regime.
References
- Original paper: Can AI Agents Agree?
- Code (anonymous repo): bcg-iclr2026
- Classical BFT background: Pease et al. (1980); Lamport, Shostak, Pease (1982), The Byzantine Generals Problem
- FLP impossibility: Fischer, Lynch, Patterson (1985), arXiv:cs/0001023
- Related LLM-consensus work: Chen et al. (2023, arXiv:2310.20151); Grötschla et al. (2025, arXiv:2507.08616); Zheng et al. (2025, arXiv:2511.10400)